
Article
Claude Opus 4.7 in Bedrock: The Important Takeaways for AWS Teams
TL;DR:
- This is not a clean model swap. Bedrock changed the model and the inference layer at the same time.
- The tokenizer changed. The same input can use materially more tokens, which affects cost,
max_tokensheadroom, and compaction thresholds. - Opus 4.7 tends to spend more tokens on harder agentic runs, so later turns can get slower and more expensive than your current baselines.
- Re-run prompts, end-to-end agent tests, quotas, and Region checks before moving live traffic.
AWS added Claude Opus 4.7 to Amazon Bedrock on April 16, 2026. For teams already using Bedrock, the real change is not the model name alone. AWS changed two things at once: the model and the serving layer under it. Bedrock is now running Opus 4.7 on its new inference engine, so treat this as a fresh evaluation cycle, not a routine version bump.
What actually changed
According to AWS and Anthropic, Opus 4.7 is aimed at four kinds of work:
- Agentic coding: stronger performance on software engineering tasks, long-horizon autonomy, and complex systems reasoning.
- Knowledge work: better results on document creation, financial analysis, and multi-step research.
- Long-running tasks: greater consistency across the full 1 million token context window.
- Vision: high-resolution image support for charts, dense documents, and screen interfaces.
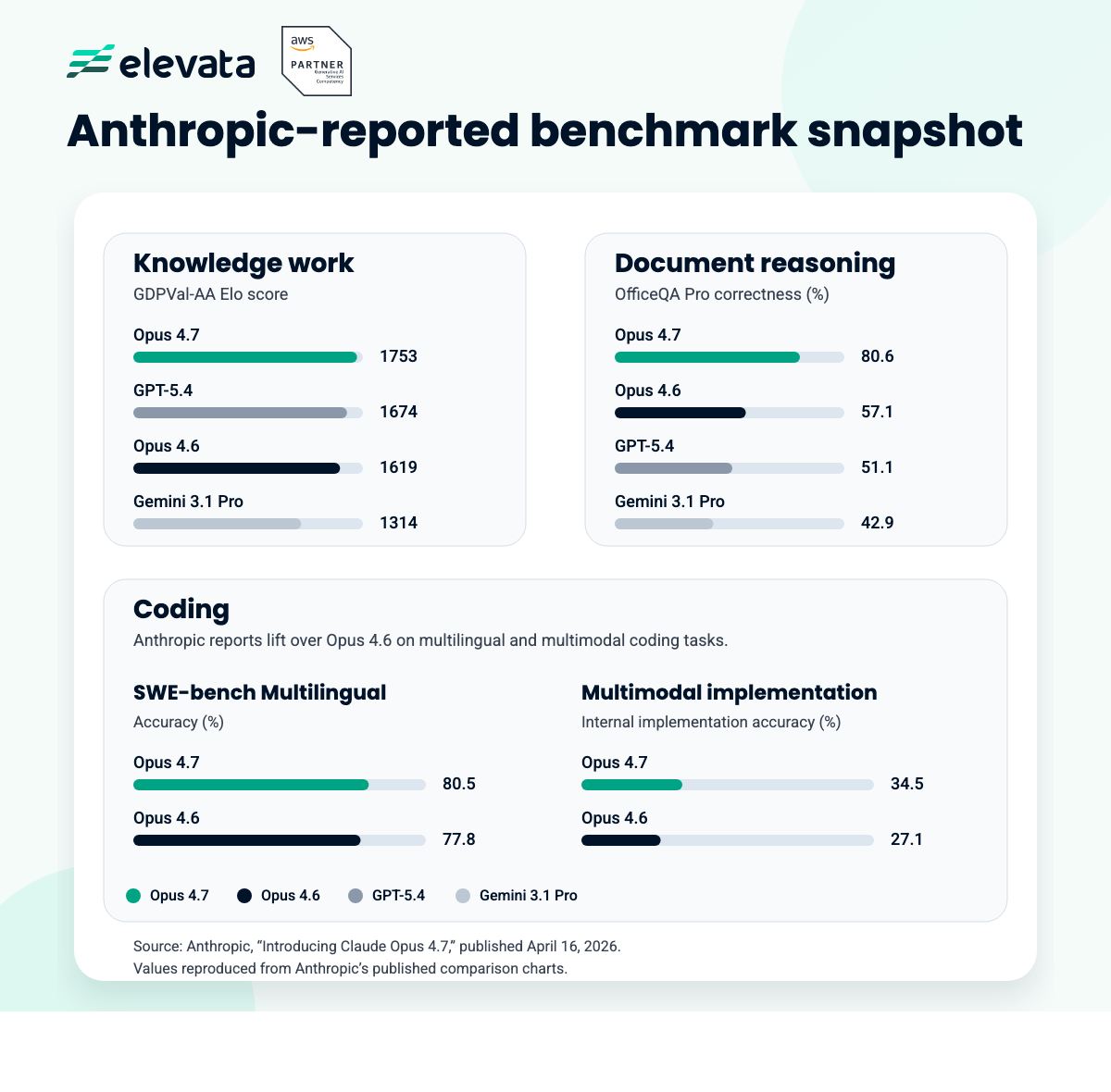
The more relevant line in AWS's own announcement is the caveat that teams may need prompt changes and evaluation harness tweaks to get the best results. In other words, do not treat this as a simple model-ID swap and do not assume your current workflow improves on its own. Re-run prompts, output rubrics, and end-to-end agent flows.
There is also a less visible change with more operational bite. In Anthropic's migration guide for Opus 4.7, the company says the model uses an updated tokenizer and that the same input can map to more tokens, roughly 1.0x to 1.35x depending on content type. Combined with the fact that Opus 4.7 tends to think more at higher effort levels, especially on later turns in agentic runs, that can move cost, latency, max_tokens headroom, and compaction behavior enough to matter in production. That is exactly the kind of change teams miss if they only look at benchmark tables.
The Bedrock layer matters as much as the model
The platform side deserves equal attention. Opus 4.7 runs on Amazon Bedrock's new inference engine, with updated scheduling and scaling logic to allocate capacity across requests.
In plain English, AWS is promising better availability for steady traffic and more headroom for services that spike quickly. During high demand, requests are queued instead of rejected, with up to 10,000 requests per minute per account per Region available immediately and higher limits available on request.
AWS also says customer prompts and responses are not visible to Anthropic or AWS operators. For privacy, risk, and compliance teams, that is a practical evaluation point, not just positioning language.
How to access it
You can test Claude Opus 4.7 in the Amazon Bedrock console and Playground. For application work, AWS exposes it through the Anthropic Messages API, Converse API, Invoke API, the AWS SDK, and the AWS CLI. The published model ID is anthropic.claude-opus-4-7.
AWS also points to Adaptive thinking, which lets the model vary its reasoning token budget based on request complexity. That matters most when a workflow moves between simple prompts and harder analytical or agent tasks.
Where it is available
At launch, AWS says the model is available in US East (N. Virginia), Asia Pacific (Tokyo), Europe (Ireland), and Europe (Stockholm). If your production stack lives in another Region, check latency, data residency, and failover before you roll this out to live traffic.
What to review before you adopt it
Before you put Opus 4.7 into production, review six things.
- Re-benchmark prompts and output rubrics. Better reasoning often changes response shape, assumptions, and failure modes.
- Test agent workflows end to end. The gains may show up over long execution paths, not in isolated prompts.
- Re-test token budgets and
max_tokensheadroom. If the same text can tokenize larger, payloads that were previously comfortable can become tight. The same applies to compaction triggers, caching assumptions, and any code path that estimates tokens client-side. - Check quotas, throughput, and Region placement. The default capacity may be enough for testing, but larger teams should request increases early.
- Pick the API on purpose. Converse is a good fit for multi-turn interactions and Guardrails. Invoke gives you lower-level control.
- Update your internal scorecard. Compare Opus 4.7 with your current model on cost per completed task, retry rate, latency, and final output quality.
Takeaway
Read this as an operational test, not just a product announcement. AWS is pairing a stronger Claude model with changes to the Bedrock layer that serves it.
If you already build on AWS, benchmark it on your own workload, in the Region you actually use, through the API you plan to keep in production. That will tell you more than a benchmark table will. If you need help structuring that evaluation or tightening a Bedrock deployment for production, Elevata can help.
Related
Continue reading
Related reading on this topic.

4/8/2026
6 min read
NVIDIA GTC 2026: What Actually Matters for AI Teams Building on AWS
Continue reading
3/31/2026
10 min read
Claude Code on Amazon Bedrock & AWS: Infrastructure Requirements, Setup & Deployment Guide
Continue reading
